Multimodal LLM using Federated Visual Instruction Tuning for Visually Impaired
ACM ICMI 2025 (Multimodal Interaction Track)
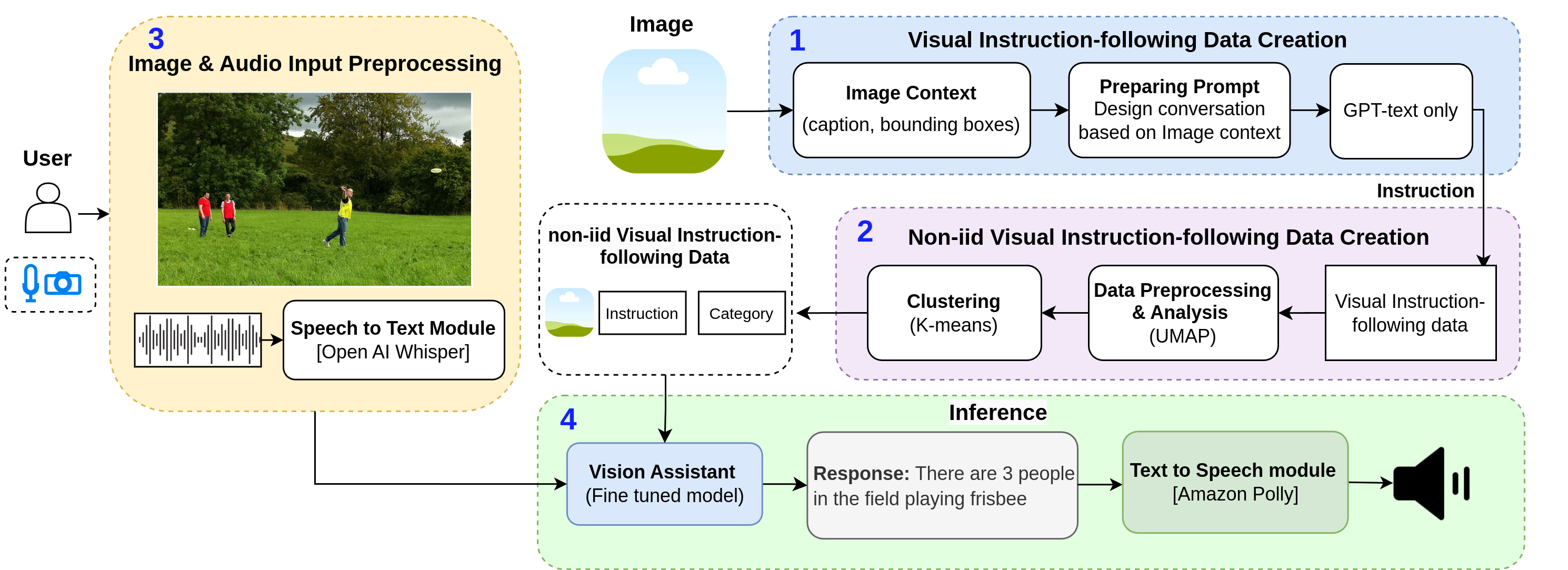
Overview
Over 285 million people globally live with visual impairment. Many struggle with tasks like recognizing scenes, reading signs, or navigating safely. The key problem is that seeing isn't understanding—just knowing there's a chair or sign isn't enough. What visually impaired users really need is contextual understanding expressed in natural language.
We present a federated multimodal assistant that respects privacy while enabling real-time scene understanding. Our approach keeps user data on device—images from homes, workplaces, and personal documents stay local. Only model updates are shared. Using efficient LoRA-based instruction tuning, we created a capable multimodal assistant trainable in ~36 hours on a single 2×A100 node. The system achieves 85% task completion in usability studies, with users reporting natural, meaningful responses.
This demonstrates that privacy doesn't have to come at the cost of performance. With federated visual instruction tuning, we get both.
Presentation Video
Key Contributions
Privacy-Preserving Design
User data stays on device. Instead of sending raw images to servers, only model updates are shared—making training both private and robust.
Visual Instruction Tuning
Teaching LLMs to see and talk by framing tasks as natural instructions—moving beyond recognition to contextual reasoning.
Strong Performance
Federated fine-tuning nearly matches centralized performance while preserving privacy and handling diverse user environments.
Efficient & Practical
LoRA-based adaptation enables training on resource-constrained devices, making assistive AI accessible and deployable.
How It Works
Our system integrates three core components that work together:
- Vision Understanding: A CLIP based encoder processes images to extract meaningful visual features
- Smart Connection: A specialized connector bridges visual information with language understanding
- Natural Conversation: A language model interprets your questions and generates helpful responses
When you send an image and question:
- Step 1: The vision encoder analyzes your image
- Step 2: Visual information combines with your question
- Step 3: The language model generates a natural answer
- Step 4: Verification ensures accuracy
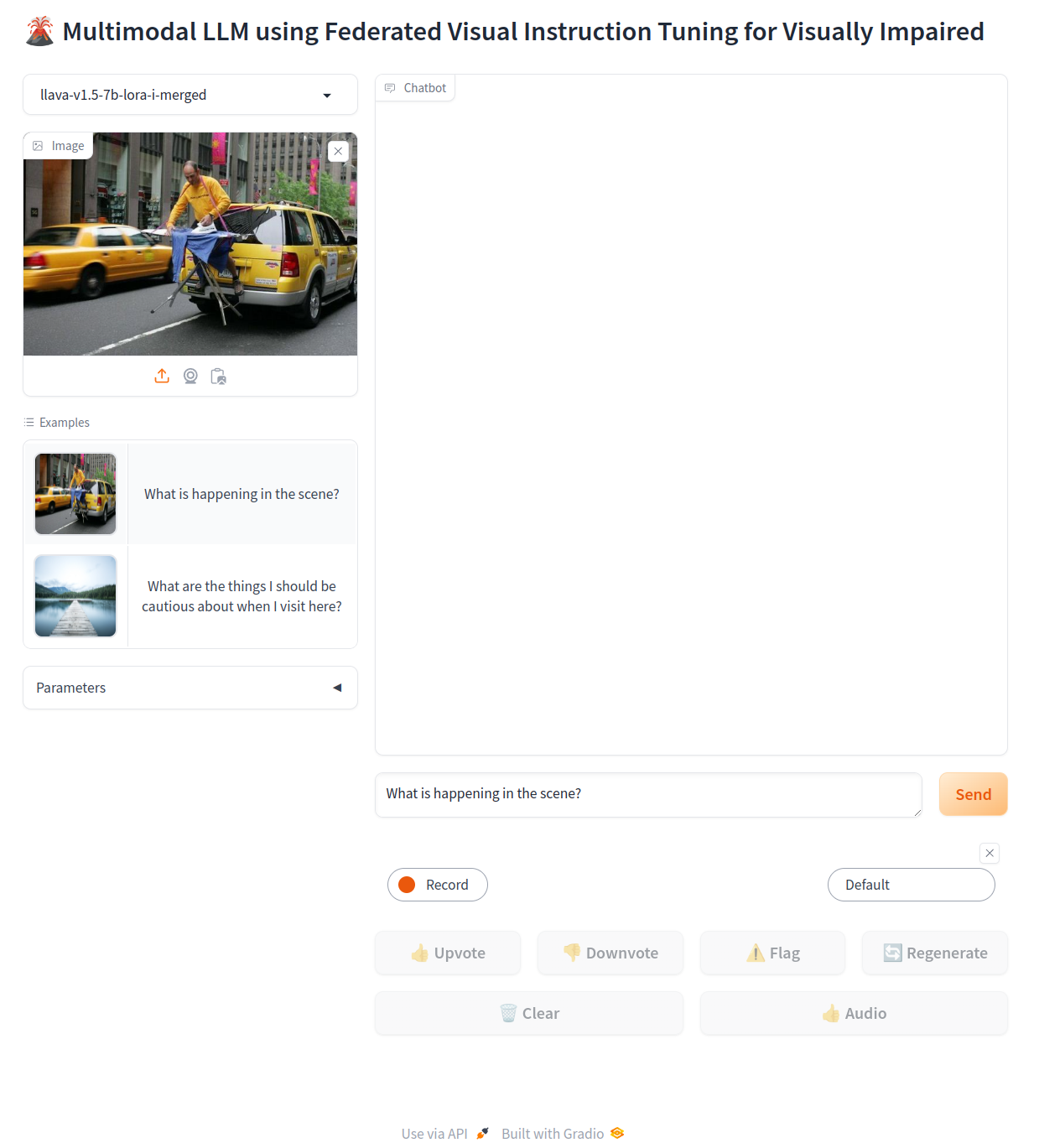
Interactive interface for real-time image analysis and assistance.
System Architecture
Vision Encoder
A powerful CLIP ViT-L/336px encoder processes images to extract rich visual features, identifying objects, text, spatial relationships, and context.
Multimodal Connector
A specialized two-layer MLP bridges vision and language, translating visual features into a form the language model can understand.
Language Model
Vicuna 7B generates natural, conversational responses based on visual information and your questions with accuracy verification.
Technical Architecture
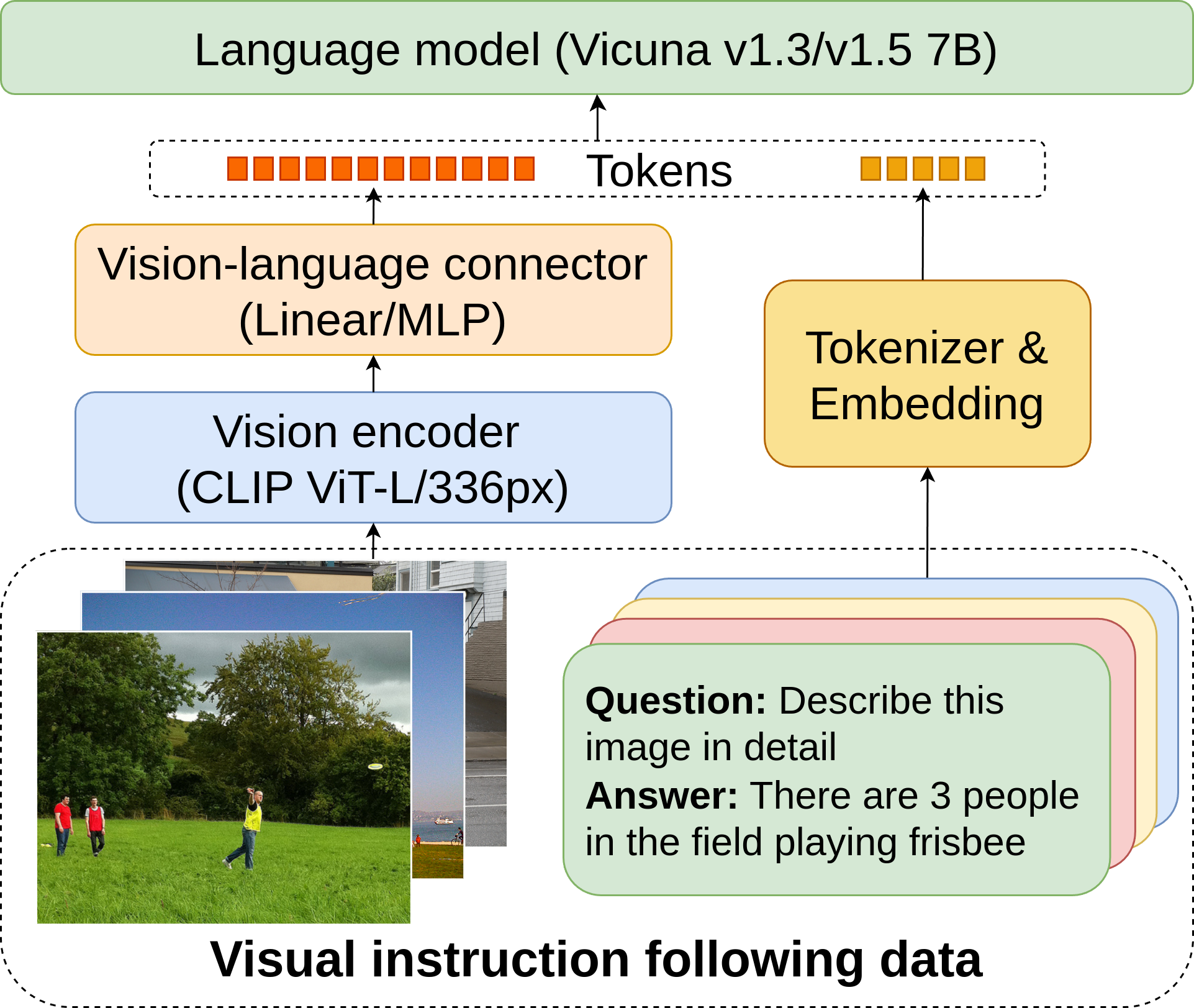
Detailed processing pipeline
Processing Flow
Visual features flow through the connector layer where they align with language embeddings. The language model then processes both the visual context and your query to generate accurate responses with verification.
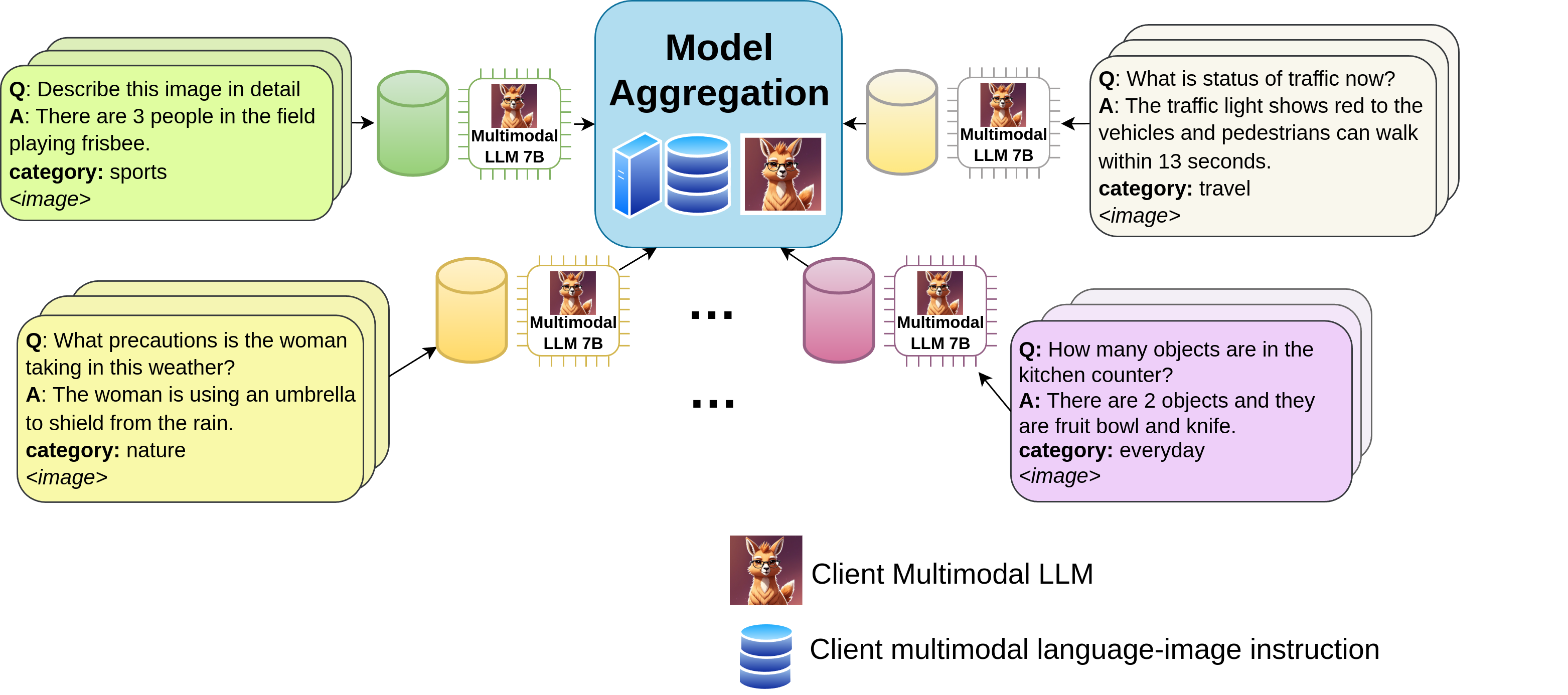
Privacy preserving training
Federated Learning
Your device trains locally on your data, then shares only encrypted model weight updates, never your actual images. Multiple devices collaborate to improve the global model while keeping all personal data private.
Real-World Performance
Usability Study
Tested with participants performing object identification, text reading, and navigation tasks. Achieved over 80% task success, fewer critical errors, and positive feedback on naturalness of responses.
Hallucination Reduction
Evaluated on HallusionBench dataset. Federated fine-tuning reduced hallucination rates compared to baseline, showing that diverse distributed data improves reliability.
Nearly Matches Centralized
Federated fine-tuning nearly matches centralized performance on OK-VQA, VQAv2, and GQA while preserving privacy. The key insight: privacy doesn't have to come at the cost of performance.
Impact & Applications
This technology opens new possibilities for independence and accessibility:
🏪 Shopping & Daily Life
Read product labels, find items on shelves, check expiration dates, and navigate stores independently.
🗺️ Navigation
Understand street signs, identify landmarks, get real-time descriptions of surroundings and obstacles.
📱 Digital Content
Access visual content on screens, understand images in documents, and engage with social media photos.
🏡 Home & Personal
Identify objects, read mail, check clothing colors, and handle everyday visual tasks with confidence.
Research & Publication
This work was presented at ACM ICMI 2025. For technical details, methodology, and complete evaluation results, please refer to our paper.
Citation
@inproceedings{10.1145/3716553.3750763,
author = {Bala, Ankith and Vereshchaka, Alina},
title = {Multimodal LLM using Federated Visual Instruction Tuning for Visually Impaired},
year = {2025},
isbn = {9798400714993},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3716553.3750763},
doi = {10.1145/3716553.3750763},
booktitle = {Proceedings of the 27th International Conference on Multimodal Interaction},
pages = {191–199},
numpages = {9},
keywords = {Multimodal Interaction; Assistive Technology; Visually Impaired; Federated Learning; Multimodal LLMs; Responsible AI},
series = {ICMI '25}
}